Using the KG
The Helmholtz Knowledge Graph is designed to make metadata across Helmholtz accessible, explorable, and reusable for a wide range of users and applications. Whether you are looking to discover relevant research outputs, analyze metadata at scale, or integrate Helmholtz data into your own tools and workflows, the KG provides multiple entry points tailored to different needs and levels of technical expertise.
The following sections provide practical guidance for each of these interaction modes. They are intended to help you get started quickly, understand the capabilities and limitations of each interface, and find solutions to common challenges. Whether you are exploring the graph for the first time or building advanced applications on top of it, these guides will support you in making effective use of the Helmholtz Knowledge Graph.
Web UI
For exploratory use, the web user interface offers an intuitive way to search, filter, and navigate through the graph. It enables users to move seamlessly between related entities—such as datasets, publications, organizations, and contributors—and to gain insights without requiring prior knowledge of the underlying data structures.
This makes it particularly suitable for researchers, administrative staff and data professionals who want to quickly explore the Helmholtz digital landscape.
SPARQL Enpoints
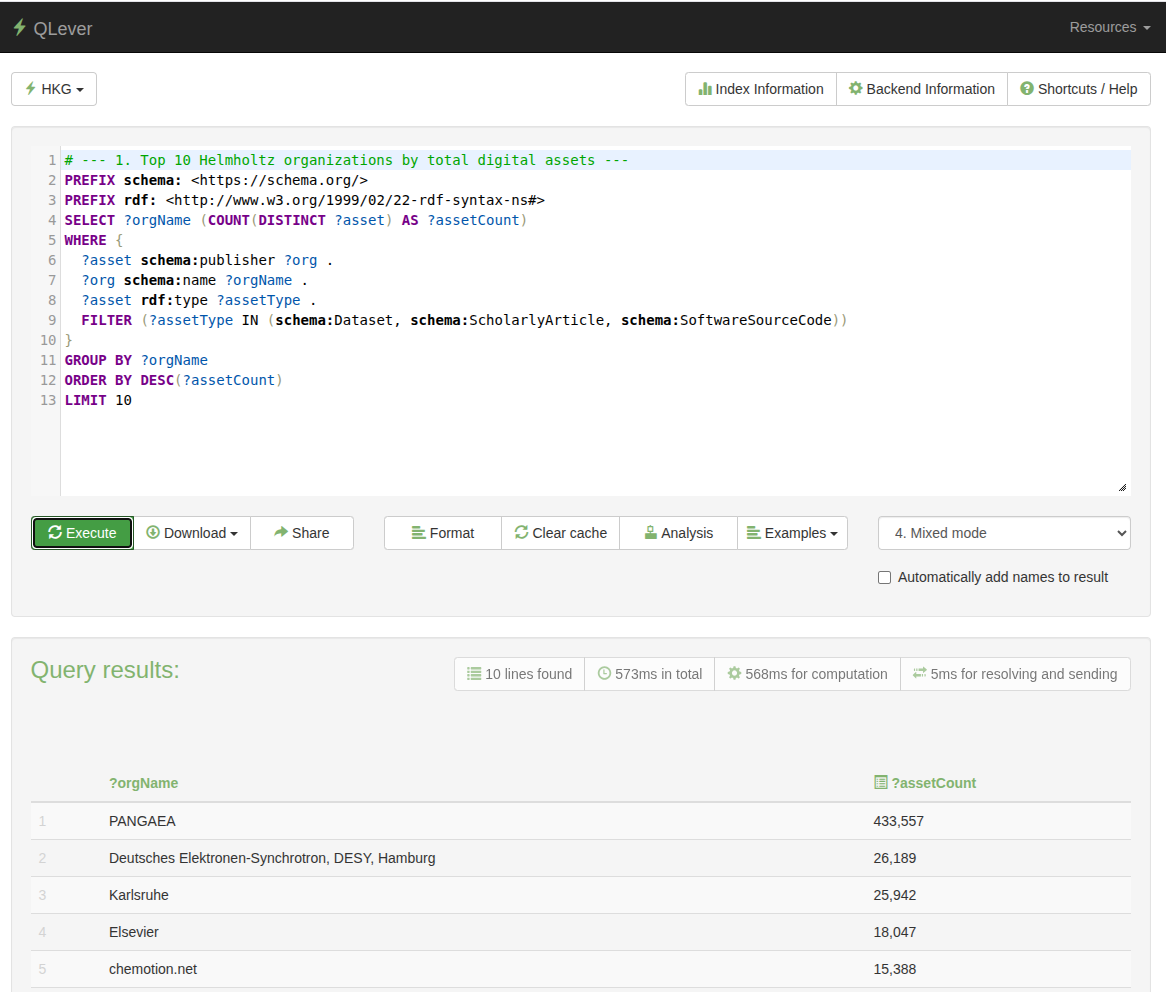
Access to the Helmholtz KG full data and structure is offered though our SPARQL enpoints. Through SPARQL queries, users can explore complex relationships, perform custom analyses, and extract precisely defined subsets of the graph. This level of access is particularly valuable for developers, data scientists, and anyone interested in working directly with the semantic structure of the data.
Storage API
To access the storage layer of the graph infrastructure, the Storage API offers authentication free read operations. Here users can retrieve raw metadata records in a structured format. This enables developers and data scientists to use the raw, unstructured data fro integration into external applications, workflows, or analyses, and supports use cases where specific subsets of the data are required for further processing.